 Since few days I started studying the Functional Programming paradigm, so I decide practicing by implementing a commonly used algorithm. Although Groovy it isn’t strictly a functional programming language, it has all the characters of a functional programming language.
Since few days I started studying the Functional Programming paradigm, so I decide practicing by implementing a commonly used algorithm. Although Groovy it isn’t strictly a functional programming language, it has all the characters of a functional programming language.
K-Means
K-Means is a method of cluster analysis which aims to partition n observations into k clusters in which each observation belongs to the cluster with the nearest mean.
Given a set of observations (x1, x2, …, xn), where each observation is a d-dimensional real vector, k-means clustering aims to partition the n observations into k sets (k ≤ n) S = {S1, S2, …, Sk} so as to minimize the within-cluster sum of squares (WCSS):
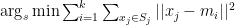
where mi is the mean of points in Si.
The most common algorithm is the Lloyd’s algorithm, it uses an iterative refinement technique.
Given an initial set of k means m1(1),…,mk(1), the algorithm proceeds by alternating between two steps:
- Assignment step: Assign each observation to the cluster whose mean is closest to it
where each xp is assigned to exactly one S, even if it could be is assigned to two or more of them.
- Update step: Calculate the new means to be the centroids of the observations in the new clusters.


The algorithm has converged when the assignments no longer change.
Implementation
One of the peculiarity of the functional programming is that the data is immutable, so any iterative algorithm is implemented using a recursive approach, often it is used one or more helper functions for the recursion.
A particular kind of recursion, named Tail call, is often used. In the tail call (or tail recursion) the recursive call is the very last statement of the function. Many languages, and more the functional languages, when using the tail call they reuse the stack frame of the previous call, this technique enhances the performances and minimizes the amount of memory used.
Implementing the iteration with a recursive helper function
The inputs of the kmeans functions are the set of the observations (points in the implementation) and the number of cluster, k. For implementing the iterative algorithm I used a helper function that is called recursively, using the tail recursion. I implemented the helper function, named “iteration”, as a named closure inside the groovy function, “iteration” receives in input the set of the centroids computed in the previous iteration and gives in output a map (where the key is the centroid and the value is a list of the points of the cluster) containing the clusters.
def kmeans(points, k) {
def iteration = {centroids->
// something is missing here
}
iteration(points.sort(false){Math.random()}[0..k-1])
}
The initial k centroids are chosen randomly from the sets of the points.
The assignment step
The first step of the iteration is the assignment, that is dividing the set of the points in k subsets assigning each point to the cluster whose mean or centroid is the closest.
def clusters = points.groupBy {p->
centroids.min {c->
[p, c].transpose().inject(0) {acc, val-> acc + Math.pow(val[0] - val[1], 2)}
}
}
The code above implements the assignment step, the groupBy method of the List sorts all collection members into groups determined by the supplied mapping closure. So in the code, clusters will contain a Map where the keys are the supplied centroids and the values are the lists of points for whom the key is the closest centroid. The closure supplied to groupBy has in input an element p of the list and gives as output the centroid closest to p.
To find the closest centroid it is useful the min method of the List, that selects an item in the collection having the minimum value as determined by the supplied closure. So what min does is to map each element of the list with a comparable value than finds the minimum of those values and gives back the associated element. The mapping function needed by min, is implemented in the line 3 of the code, this line computes the squared distance of the point p from the centroid c as 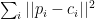
The update step
In the update step the means of each clusters are updated, in other words after the previous assignment it is possible that the previous centroids aren’t anymore at the center of the cluster, so the update step can be seen as moving the centroids back to the center of the respective cluster.
def newCentroids = centroids.collect {
clusters[it].transpose().collect() { it.inject(0) {a, v-> a + v } / it.size()}
}
The code above implements the the update of the centroids. This code finds the new position of the centroids. The collect of the List produces a new List where each element i it is obtained as the result of a function applied on the element i of the original List. The function provided computes the position of the new centroid as the geometric center of the cluster.
Testing the convergence
A criterion for determining the convergence is to test that the centroids didn’t move from the previous iteration.
def d = [centroids, newCentroids].transpose().collect() { c_on ->
c_on.transpose().collect() { ce_on ->
Math.pow(ce_on[0] - ce_on[1], 2)
}.inject(0){a, v->a+v}
}
if(d.findAll(){it > 0.000001}.size() == 0) clusters
else call(newCentroids)
The lines 1-5 compute the squared distance between the actual (newCentroids) and the previous (centroids) position of each centroid.
The last two lines check if there was any movement, that is counts the elements from the list of the distances that are greater than a given epsilon. If no change is found it the obtained clusters are returned (notice that is not needed to explicitly use the return statement) otherwise a new iteration is started.
Putting all together
The following code is the complete implementation of KMeans.
def kmeans(points, k) {
def iteration = {centroids->
def clusters = points.groupBy {p->
centroids.min {c->
[p, c].transpose().inject(0) {acc, val-> acc + Math.pow(val[0] - val[1], 2)}
}
}
def newCentroids = centroids.collect {
clusters[it].transpose().collect() { it.inject(0) {a, v-> a + v } / it.size()}
}
def d = [centroids, newCentroids].transpose().collect() { c_on ->
c_on.transpose().collect() { ce_on ->
Math.pow(ce_on[0] - ce_on[1], 2)
}.inject(0){a, v->a+v}
}
if(d.findAll(){it > 0.000001}.size() == 0) clusters
else call(newCentroids)
}
iteration(points.sort(false){Math.random()}[0..k-1])
}
Results
The following pictures show the output of KMeans for a set of two dimensional observation, and a value o k equals to 2.
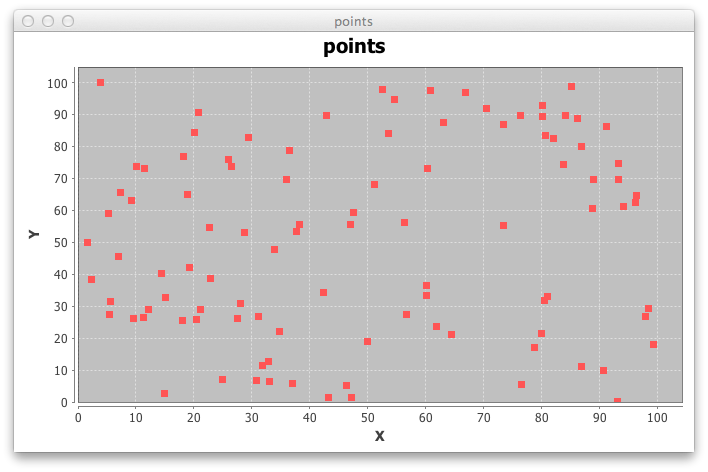
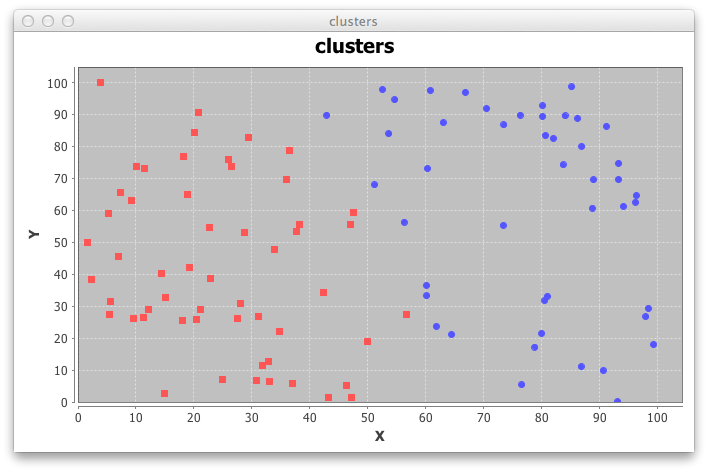
The complete source code kmeans.groovy uses JFreeChart for displaying the input and the output.
